Figure 1: Musicbee after the Genre classification
This post is about how did I organise my music library by genre. I have not done it for the sake of organisation (well, maybe a little), but because it is part of a bigger project. This (bigger) project is to have an old radio reconverted with a Raspberry PI in such a way that turning the dial will let the user choose different radio stations. Each radio station will play a set of songs, and it will be defined by a combination of genre and decade.
Because the organisation serves a purpose to the project, the classification had to be done with a set of rules (aka The Radio Rules!):
- Few genres. Between 15 and 25.
- Each genre should have a decent pool of songs. I do not want a radio playing 6 songs time after time, I already have KISS FM Spain for that.
- Each song must be categorised using only one genre.
Easy! Well, this task has consumed most of my free time since September 2020, and it isn’t over yet!
But Ricardo, shall I have any learning expectations from this post? Well, mostly no. This is a small resume of what you will find in the post:
- An explanation on why classifying by genre is pointless and most people have already given up.
- The currently existing software to automatise this task.
- Me ignoring every piece of software and instead, using Plato’s theory to classify my library in a list of genres.
- How to get a CSV file with information about your library collection.
- How to use R and last.fm API to retrieve information about an artist genre (this is the only section in which, potentially, you will actually learn something)
Why classifying by Genre is complicated.
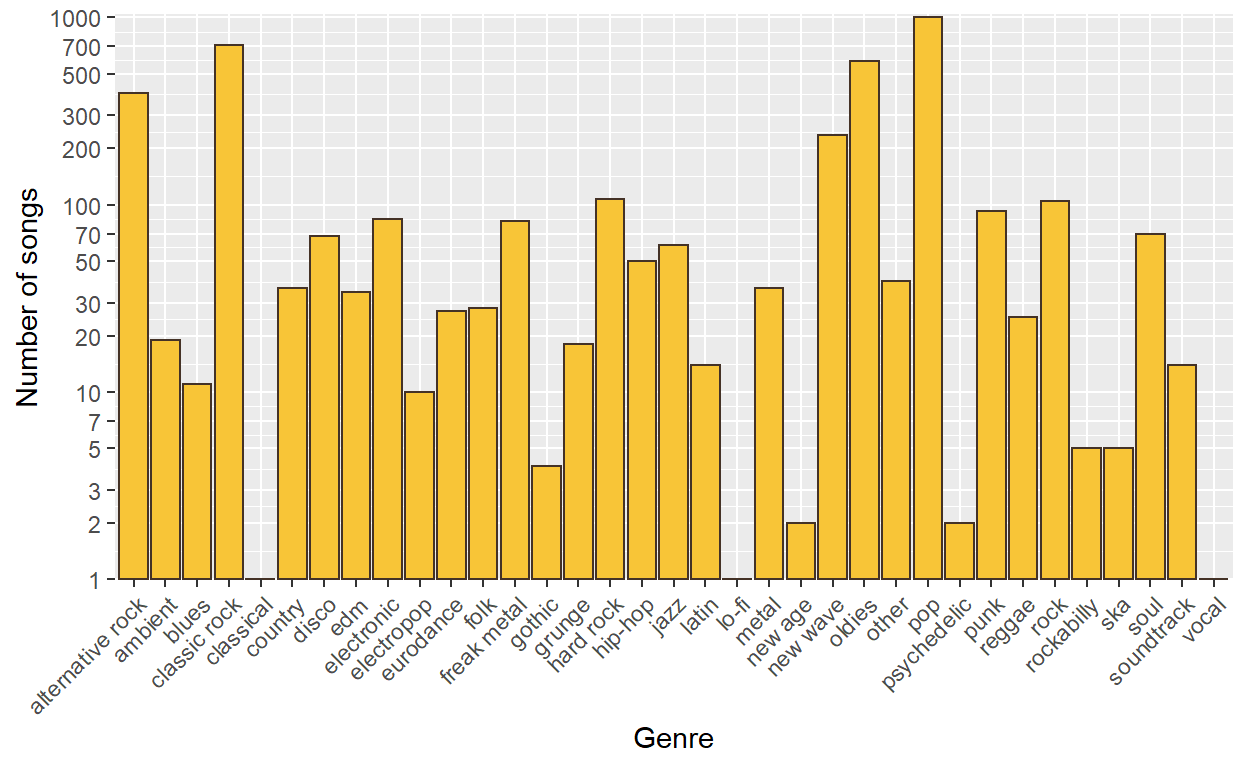
Figure 2: Library Statistic
When I started this task I used my favourite search engine to see how can it be done. I ended up in some music forums and a lot of answers were that people gave up on classifying by genre. Why? Because genres are subjective. If I ask you who is the original artist of “Girls just wanna have fun”, there is only one right answer: Robert Hazard.1 You don’t get a simple answer when doing the same question about the genre. If you are a fan of Electronic music you might want to tag all the different styles (House, Ambient, Disco, Dub, Electro Swing…) whilst for another person (me!) all those styles might go under the tag EDM (In my case, the EDM tag is to group modern electronica like Techno, House, etc., and differentiate them from classic electronic music like Tubular Bells or Michael Jean Jarre).
Another problem is the gradualness of genres. Musicians have an inherent problem with making music that can be categorised into a nice simple genre. Those little bastards will try to have their own “style” and do you know how they do that? Yes, exactly, they got two genres and mix them (and not even 50%/50%). If a band now combines punk with metal. Is it punk? Is it metal? Is it a bird? Is it a plane? Is it a birdplane? This could not be a problem, but it collides with the set rule of only one genre per song.
This leads to the following quandary, uniqueness. Some artists have managed to create a genre so specific that no other band in the world plays. This occurs more often than I would like it2. Do I really want to classify Cartoons in the technobilly tag? No, I don’t, why anybody would like that? Plus it collides with each genre should have a decent pool of songs rule. A decision was taken, if some musician managed to invent a genre so specific that couldn’t be assigned to a broader genre(a.k.a. piss me off), then, their songs will be exiled into the wretched genre of “other”, and more likely they won’t be played again!
Resuming, classifying genres ain’t easy because of subjectivity, gradualness and uniqueness. So how did I solve this? Come up with a predefined list of genres. The list must have enough genres to successfully divide the music collection into sensible categories and adapt to my own criteria and library.
So the first step to start is, you need to come up with a list of genres. My starting point was the ID3v1 list of genres. The list contains a nice 80 tags to start with. Remove some tags (Top 40, Gospel) and add some other tags (EDM). Whatever list you come with here, you will change it later. This process is mostly iterative.
You don’t know how many songs will you have in a genre until you start. This translates into ending up with some genres with very few songs, and others including one-third of the music collection. In my case: New Age, Psychedelic, and Vocal contain less than 20 songs combined. Whilst, Classic Rock has 710 songs, and the almighty Pop has 1015 songs. Classic Rock and Pop are 43% of my library.
I am currently reiterating all the process and trying to divide Pop into other subgenres like New Wave (already done) or electropop (currently working on this).
Software to auto-sort by Genre

Figure 3: Can’t someone else do it?
But can’t someone else just do it? Technically yes, but it will be a subpar job. The subjectivity, graduality and uniqueness will come to and screw up with your plans of letting a tool work for you. But if you do not trust me you can go and test them by yourself. Do what I did, create a 50 songs sample (Trial periods are limited to a certain amount of songs) and check if you are happy with their results.
I will recommend you to start with the free Music Brainz Picard. This software will scan your music collection, assign them a “magic music hash id”. And compare with their own community giant database collection to retrieve the information.
But Ricardo, what if I think that you are a case of long pockets and short arms? What if one could spend some of their hard-earned sterling pounds and exchange them for goods and services. Services like finding a tool that just does it? Well, good news is that there are plenty of paid alternatives.
Do not get me wrong, the tools work quite alright, almost like magic. But there are two problems:
- They cannot work unattended, and if I need to revise everything they suggest me to do, the process is as slow as doing it by myself.
- The way they work collides with my three radio rules.
Getting philosophical about music classification
I decided to assign every artist to a genre (as opposed to classify each song). The only exception in my library is the artist Dover, they started making rock music and later on (with plenty of controverse) moved to electropop.

Figure 4: Plato listening to some form songs
But then I started to get philosophical. How can I determine what is Rock from what it isn’t? Is it Aerosmith rocker than Dire Straits? But why make myself such a question when great thinkers have already discussed plenty of theories? So in a nod to Plato’s theory of forms, I decided to give to every genre a master song. The master song will act as an “Idea” or “Form” of the genre. Like it is the only true representation of that genre.
When I will have doubts about an artist being one or another genre, I will make myself the question, if I was the Radio Station DJ of the genre, will I play it next to the master song? If they couldn’t be played next to any master song, they would be exiled into the “other” tag.
Are you curious to know my list of “Form songs”. There you have.
Less philosophy and more coding!

Figure 5: Time to code!
I have written this post to teach philosophy and code in R… and I’m all out of theories.
We need to pass our music library info to R, so we need a CSV file with information about our library. Tagscanner is our man. Scan your library, and in the export tab, save it as an “Excel friendly” CSV file. Don’t forget to check the UTF-8 with DOM option. Mind that from this moment until you finish, you must not modify your library by adding, removing or editing any file here.
Then we need a database to get information from. Get a last.fm API so we can access their database and load it into our R code. Sign in for an API request and get your API key, your API key is a hexadecimal number that should look similar to this one “0123456789abcdef0123456789abcdef”, and gives you permission to use their database.
If you don’t have R and Rstudio ready on your computer, stop making bad decisions in your life and go download and install them. You will also need the urltools and jsonlite libraries. We will be creating some functions that will help us to retrieve information from last.fm database.
library(urltools)
library(jsonlite)
# Add your Last.fm API Here
lastFM_API = "0123456789abcdef0123456789abcdef"
# This function returns the JSON URL for certain Artist
build_artist_info <- function(artist,
api_key= lastFM_API,
base = "http://ws.audioscrobbler.com/2.0/"){
base <- param_set(base, "method", "artist.getInfo")
base <- param_set(base, "artist", URLencode(artist))
base <- param_set(base, "api_key", api_key)
base <- param_set(base, "format", "json")
return(base)
}The function: build_artist_info(artist = "Aqua") generates a URL pointing to the Artist requested JSON file with information about them. If the artist doesn’t exist, you will get an URL but it won’t return anything. Copy this URL into Firefox so you can take a look at the JSON file and familiarise yourself with it. But don’t forget that we don’t need to load the JSON in firefox. We need the data to be in R. The way to do this is using the function fromJSON().
fromJSON(build_artist_info(artist = "Aqua"))This function will read the JSON, and convert it to an R format (list of lists). Don’t hesitate to save this into a dummy variable and check the info in the environment panel of Rstudio, it shouldn’t differ from what you saw on Firefox. To access the top 5 last.fm genre is as easy as navigating through the data to:
fromJSON(build_artist_info(artist = "Aqua"))$artist$tags$tag$name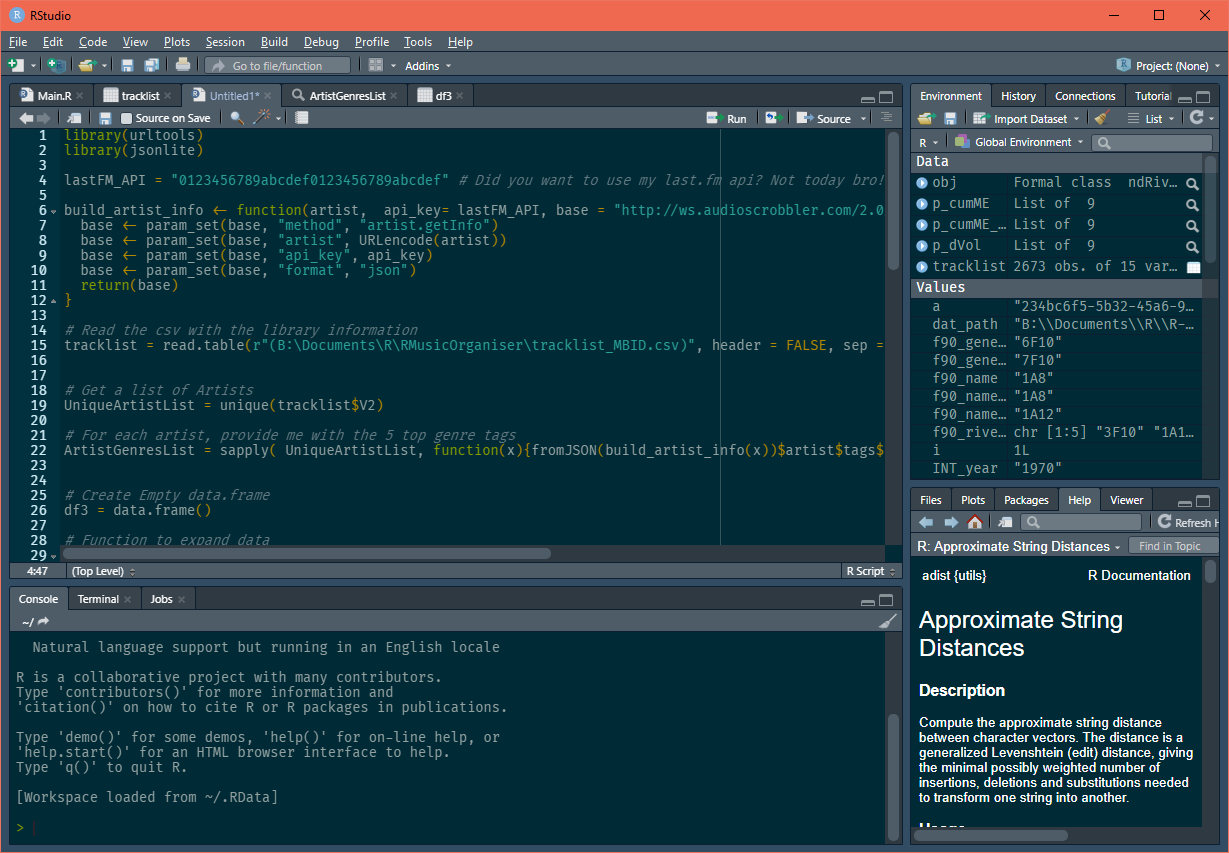
Figure 6: Rstudio showing my real last.fm API
With our new superb functions, we are ready to import the tracklist from step 1 into R and start getting genres! You will have to read the tracklist without a header because Tagscanner doesn’t give one. There are a few peculiarities on my example code snip shown below. I am not reading the first row as column names (Tagscanner default output), that my separator is “;” (because I am in a Spanish computer), I am forcing reading every column as a character (to avoid having to deal with factors) and forcing the file encoding (to UTF-8-DOM, as I asked you before).
# Read the csv with the library information
tracklist = read.table(r"(B:\Doc...\tracklist.csv)",
header = FALSE,
sep = ";",
fileEncoding = "UTF-8-BOM",
colClasses = rep("character",14))
# Get a list of Artists
UniqueArtistList = unique(tracklist$V2)
# For each artist, provide me with the 5 top genre tags
ArtistGenresList = sapply( UniqueArtistList, function(x){fromJSON(build_artist_info(x))$artist$tags$tag$name})Depending on the size of your artist list, this command can take a while to run, so it wouldn’t hurt trying in a subset of artists first. You will end up with a list of artist, which contains a list of 5 tags, or an empty list if they couldn’t find the artist (likely you wrote the artist name incorrectly).
At this point, I decided to code some really fancy scripts to auto-tag everything based on few rules (like checking decade and genre with my list of genres, and prioritising one tag over others tag, condense them into a single tag, etc…). Remember what I said about the tools that help you doing the classification? Yes, they suck! Well, turns out that my script was doing a subpar job too. Chances are that you end up having to review all information so I decided to export all info into a spreadsheet instead, and go fully manual from there.
This piece of code is to get a data frame with the artist, the 5 genres and a score for each one (starting at 0). The score should help you decide which genre is more suitable, more details below.
# Create Empty data.frame
df3 = data.frame()
# Function to expand data
expand_genre_todf <- function(x){
y = unlist(x)
if (length(y) == 5) {
res = data.frame(Artist = names(x),
genre1 = y[1],F1 = 0,
genre2 = y[2],F2 = 0,
genre3 = y[3],F3 = 0,
genre4 = y[4],F4 = 0,
genre5 = y[5],F5 = 0,
row.names = NULL)
} else {
res = data.frame(Artist = names(x),
genre1 = NA,F1 = 0,
genre2 = NA,F2 = 0,
genre3 = NA,F3 = 0,
genre4 = NA,F4 = 0,
genre5 = NA,F5 = 0,
row.names = NULL)
}
return(res)
}
# Build dataframe
for (i in 1:length(ArtistGenresList)) {
df3 = rbind(df3, expand_genre_todf(ArtistGenresList[i]))
}The scoring system can be as complicated as you want, I decided to keep it simple3. The score will be 0 if the last.fm genre is not in my master genre list and 1 if it is. How do we do that? String comparison! Well almost that. The code shown below is a little bit more complicated than just comparing two strings, I called it “the smarter string comparison”. Don’t judge me, I need to keep coming with those catchy names to keep you reading
Why the smarter string comparison? A simple string comparison between “hip-hop” and “Hip Hop” would give me a false, which I don’t want. To solve this, I am converting everything into capital letters, and generating a coefficient between them with the function adist and the number of characters to check if the tags are similar enough. The value of 0.2 was found after trial and error, and consistently produced good results with almost no false positives. If my Fortran90 teacher who (tried to) taught me to avoid using magic numbers reads this post, I am really sorry Don Requena, it will not happen again.
# Read our list of genres
genrelist = read.table(r"(B:\Documents\R\RMusicOrganiser\_ss\GenreList.csv)",
header = FALSE,
sep = ",",
fileEncoding = "UTF-8")$V1
# Add filtering
for (i in c(2,4,6,8,10)){
for (j in 1:nrow(df3)){
xg = toupper(df3[j,i])
if (!is.na(xg)){
if (any(adist(xg,toupper(genrelist))/nchar(xg) < 0.2)) {df3[j,i+1]=1}
}
}
}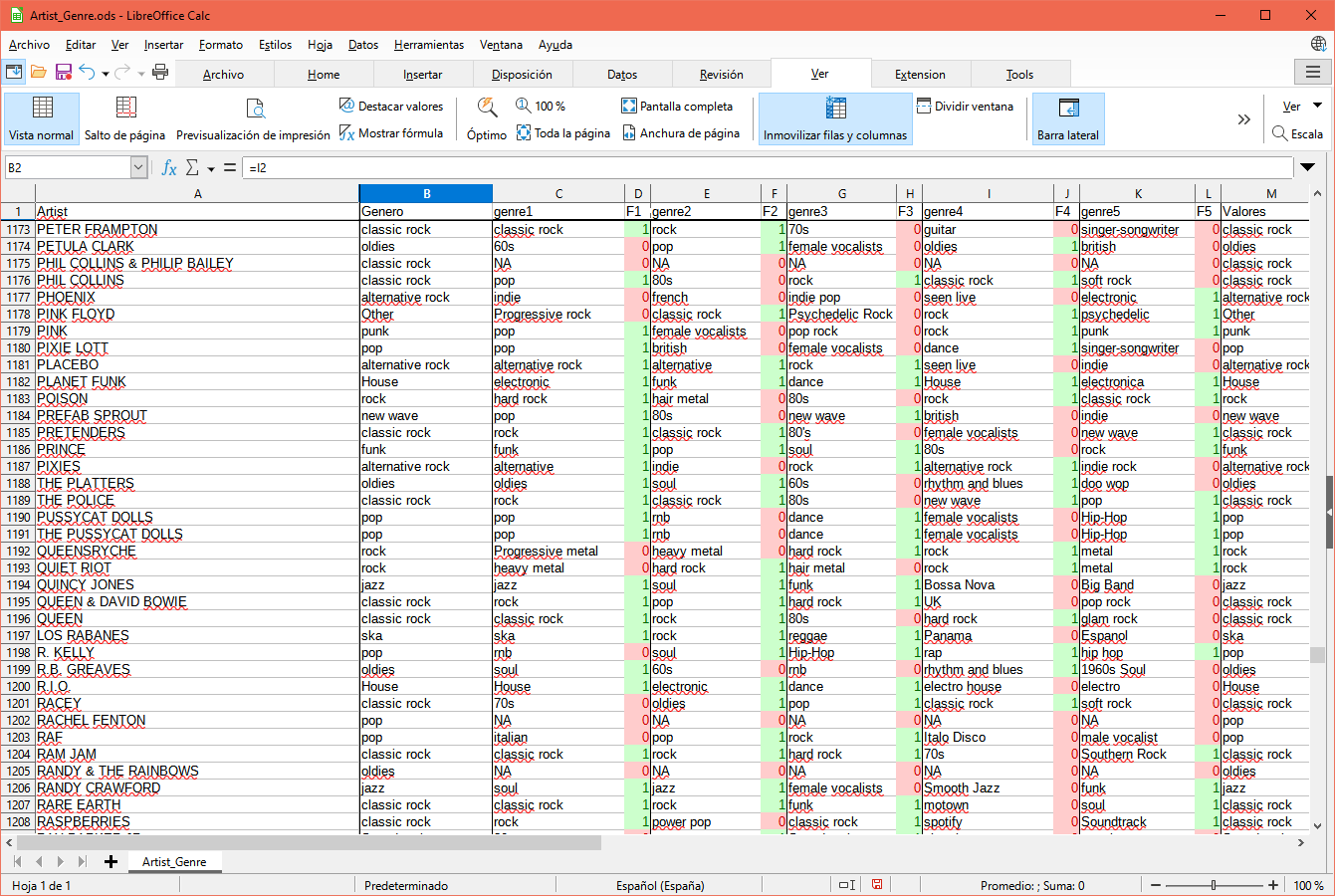
Figure 7: Libre Office with the outcoming file
And we can end up by writing this file into a CSV that we can open with your favourite spreadsheet program.
write.table(df3, file = r"(B:\Documentos\GitHub\RMusicOrganiser\Artist_Genre.csv)",
sep = ",",
row.names = FALSE)From here, there is a lot of listening to the music, assign a genre, rinse and repeat. Several months later, if you manage to finish this task instead of playing the three Mass Effect games in a row (cough…, cough…), you would need to update the original tracklist.csv. Update the genre column with your new genres, and use TagScanner to import the information into the library. Hence the importance of not updating, adding or removing songs, or the whole process would be screwed.